Proteins and nucleic acids
© Anders Skovly 2024
This article provides an introduction to the structure and function of proteins and nucleic acids. The following articles on transcription and translation builds upon information presented here.
The many functions of proteins
Proteins are interesting due to the many tasks they are capable of performing, and due to their important role in hereditary traits and diseases. Her are some examples:
Create contraction of muscle
A muscle is filled with alternating bundles of myosins and actins, two types of long proteins. When a muscle is relaxed, the end of each myosin is connected to the end of an actin. Upon receiving a signal from a nerve, each myosin will begin to move along actin in such a way that the proteins will overlap more and more, creating contraction of the muscle.
Produce alcohol
Yeast utilize Hexokinase and eleven other proteins to catabolize (break down) glucose to CO2 and ethanol. It is this process that forms that basis for production of alcoholic beverages. The catabolism generates adenosine triphosphate (ATP), a molecule that acts as a driving force for many other processes of the yeast. (Humans also use ATP, for example for driving the movement of myosin along actin, but humans cannot generate ATP by catabolizing glucose to ethanol.)
Control the blood sugar
When a person's blood glucose (blood sugar) reaches a sufficiently high concentration, specialized cells in the pancreas will release insulin-proteins into the blood. Insulin is transported by the bloodstream throughout the body and can bind to receptor proteins on muscle cells. Such receptor proteins consist of one part exposed on the outside of the cell and one part exposed on the inside.
Binding of insulin to the outer part causes a structural change in the inner part. This triggers molecular reactions inside the cell, leading to increased transport of glucose from the blood into the cell, and to increased conversion of glucose to glycogen (a large molecule acting as energy storage inside the muscle cell). Transport of glucose into the cell is carried out by GLUT4-proteins in the cell membrane, and increased transport of glucose is caused by an increase in the quantity of GLUT4.
Convert chemical energy to light
Fireflies generate light with the protein luciferase together with a molecule called luciferin. Luciferase restructures luciferin into a different molecule in a process that simultaneously release one single ray of light (one photon, light particle). This also requires oxygen and ATP.
Sense different colors
The retina of the human eye is filled with cells containing photoreceptors. Every photoreceptor is an opsin-protein covalently bound to a molecule called retinal. If the retinal is hit by a ray of light and absorbs this light it will undergo a structural change, which in turn induces a structural change in the opsin. This triggers further molecular reactions, culminating in the generation of a nerve signal that travels to the brain.
Cells with photoreceptors are divided into four groups. One group has yellow-green photoreceptors, another group has green ones, a third group has blue ones and a fourth group has green-blue ones. Cells with yellow-green, green, and blue receptors are used together to provide color vision, while cells containing green-blue receptors are used to provide night- and side vision.
The descriptions yellow-green, green, blue, and blue-green does not refer to the color of the photoreceptors, but rather to the type of light they absorb most efficiently. For example, green receptors absorb green light more efficiently than other colors of light. This means that these receptors undergo the structural change most rapidly when exposed to green light. The yellow-green receptors are often called red receptors, as it was previously believed that they absorbed red light most efficiently.
All photoreceptors contain identical retinals. The reason they absorb different colors is that they contain four different opsin proteins. The opsin influences which color of light the bound retinal absorb most efficiently, and each of the four opsins has a somewhat different influence on the retinal, resulting is absorption of four different colors.
Red-green color blindness is a heritable condition where a person cannot separate red from green, and is caused by the lack of a functional opsin in the green or yellow-green photoreceptors.
Movement of bacteria
Some bacteria have a tail called flagellum (plural flagella) built from many different proteins. Some of these proteins are located in the cell membrane and constitute a molecular engine that can rotate in the plane of the membrane. Outside the cell is a long propeller, built from many copies of the flagellin-protein, which is attached to the engine. This propeller engine tail allows a bacterium to move ("swim") through water.
The structure of proteins
The task performed by a protein depends on its three-dimensional structure, which is determined by how the protein has been assembled. All proteins are assembled from amino acids, small molecules where a carbon is covalently bound to both a primary amine and a carboxylic acid. The same carbon is also bound covalently to a hydrogen and to a so-called variable group, whose atomic structure varies between different amino acids. Some organisms assemble their proteins from twenty different amino acids, while other organisms use the same twenty plus one extra (Selenocysteine, the "twentyfirst amino acid").
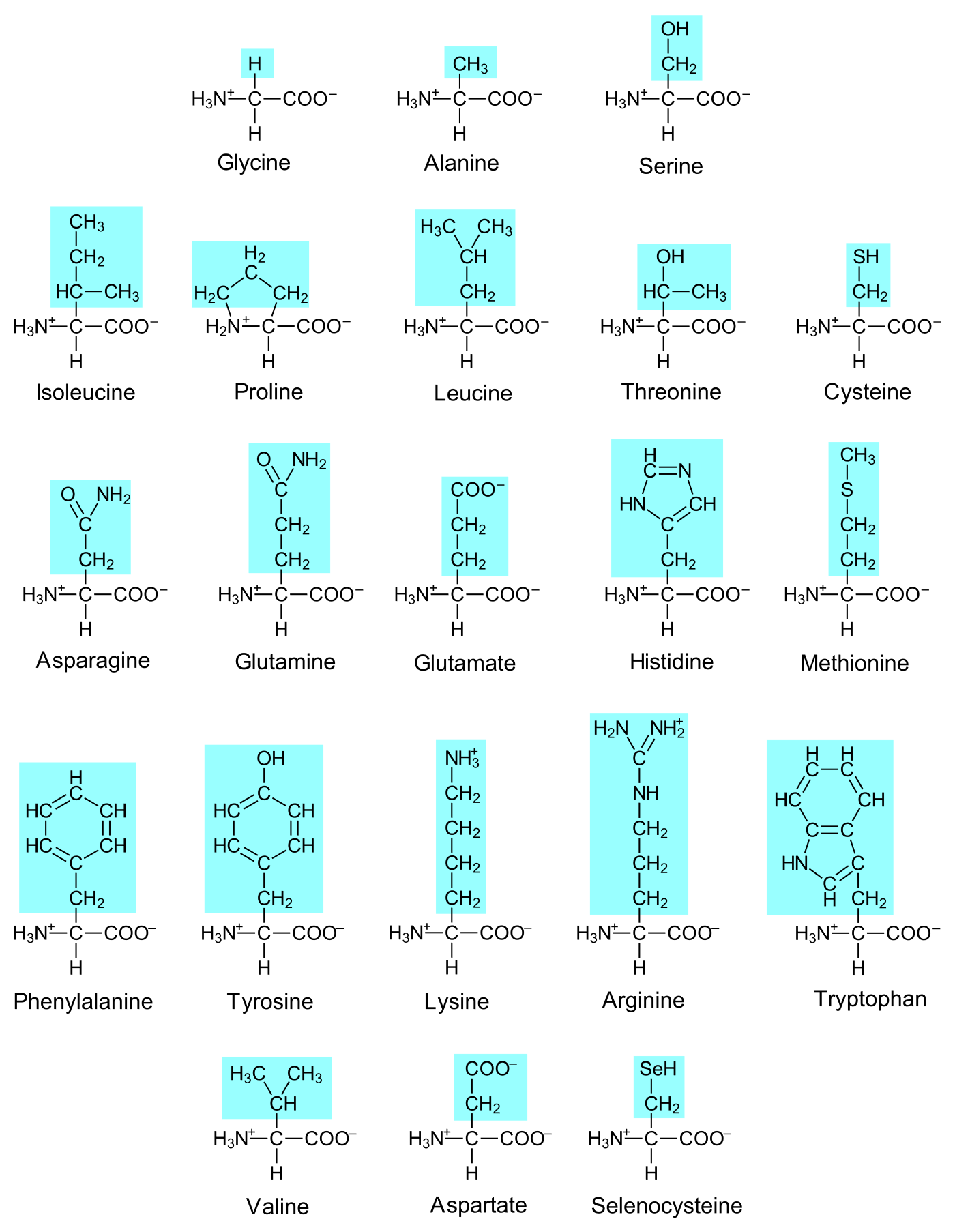
A covalent bond can be established between the amine of one amino acid and the carboxylic acid of another amino acid. Each amino acid can therefore bind up to two other amino acid. When amino acids bind together they create a linear chain called a protein. The order of the amino acids in the chain is called the amino acid sequence of the protein, and this sequence determines the three-dimensional structure of the protein, and hence its function (the details of this will be the focus in a later article).
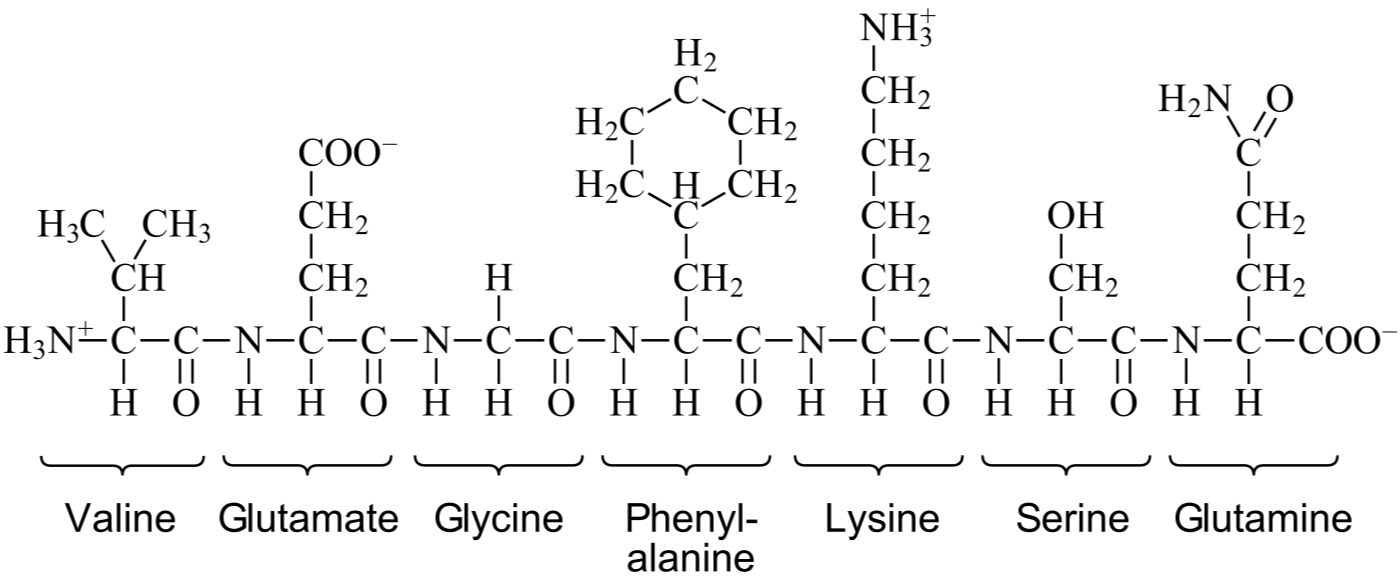
The ability to grow and reproduce is one of the defining characteristics of a living organism. For a cell to grow and divide it must be able to synthesize more proteins, but although proteins can accomplish many tasks they cannot create copies of themselves on their own. For assembly of proteins with specific amino acid sequences the cell needs nucleic acids, meaning RNA and DNA (ribonucleic acid and deoxyribonucleic acid).
The structure of DNA
Whereas a protein is assembled from amino acids, a DNA is assembled from nucleotides. A nucleotide is a small molecule comprised of a deoxy-ribose, a phosphate, and a nucleobase (usually just called a base). The deoxyribose contains five carbons which are identified by numbers: 1'-carbon, 2'-carbon, 3'-carbon, 4'-carbon, and 5'-carbon. The 1'-carbon is covalently bound to the base while the 5'-carbon is covalently bound to the phosphate. The base varies among different nucleotides, comparable to the variable group in the amino acids. The most common bases are adenine, cytosine, guanine, and thymine (abbreviated A, C, G, and T).
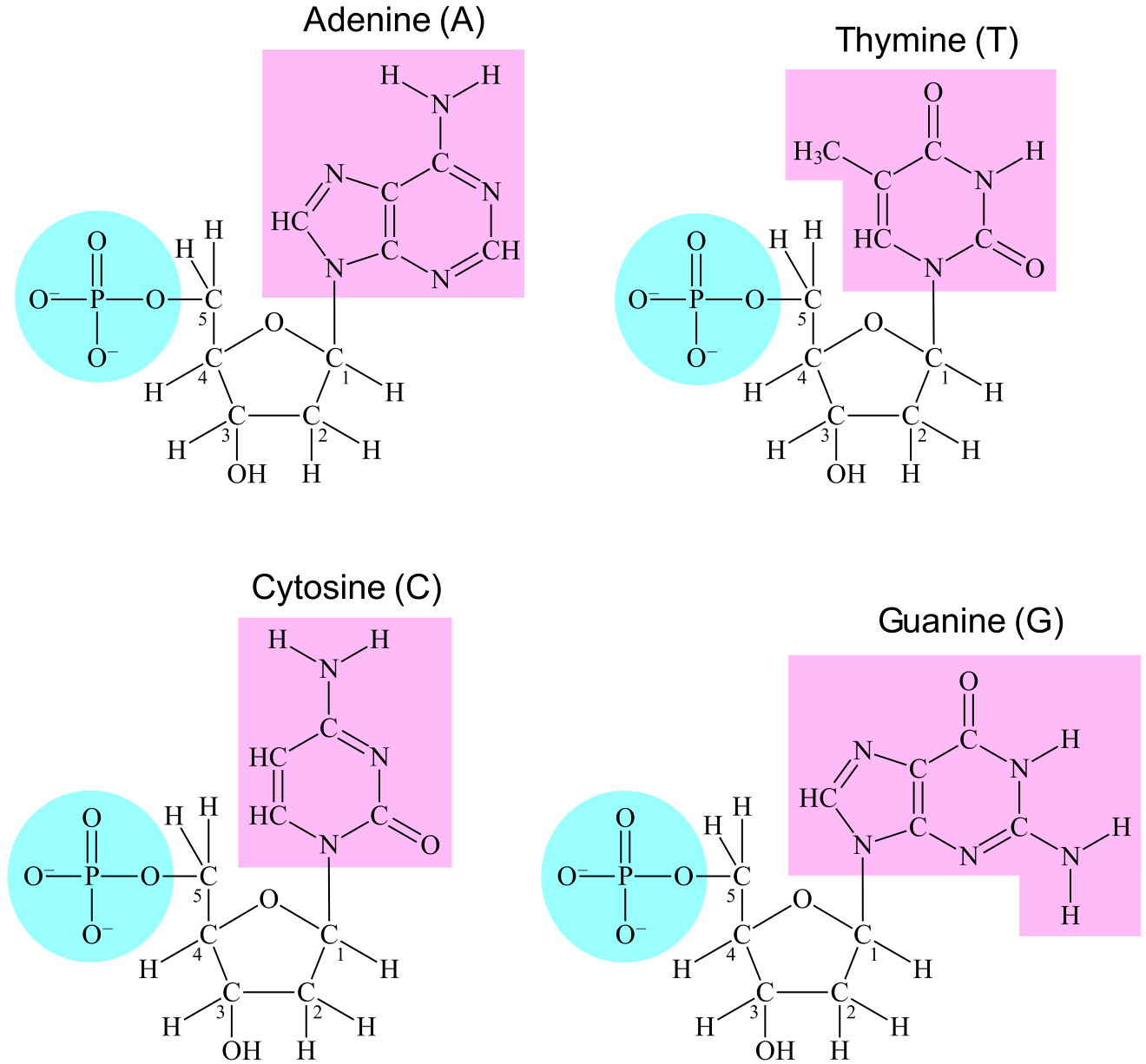
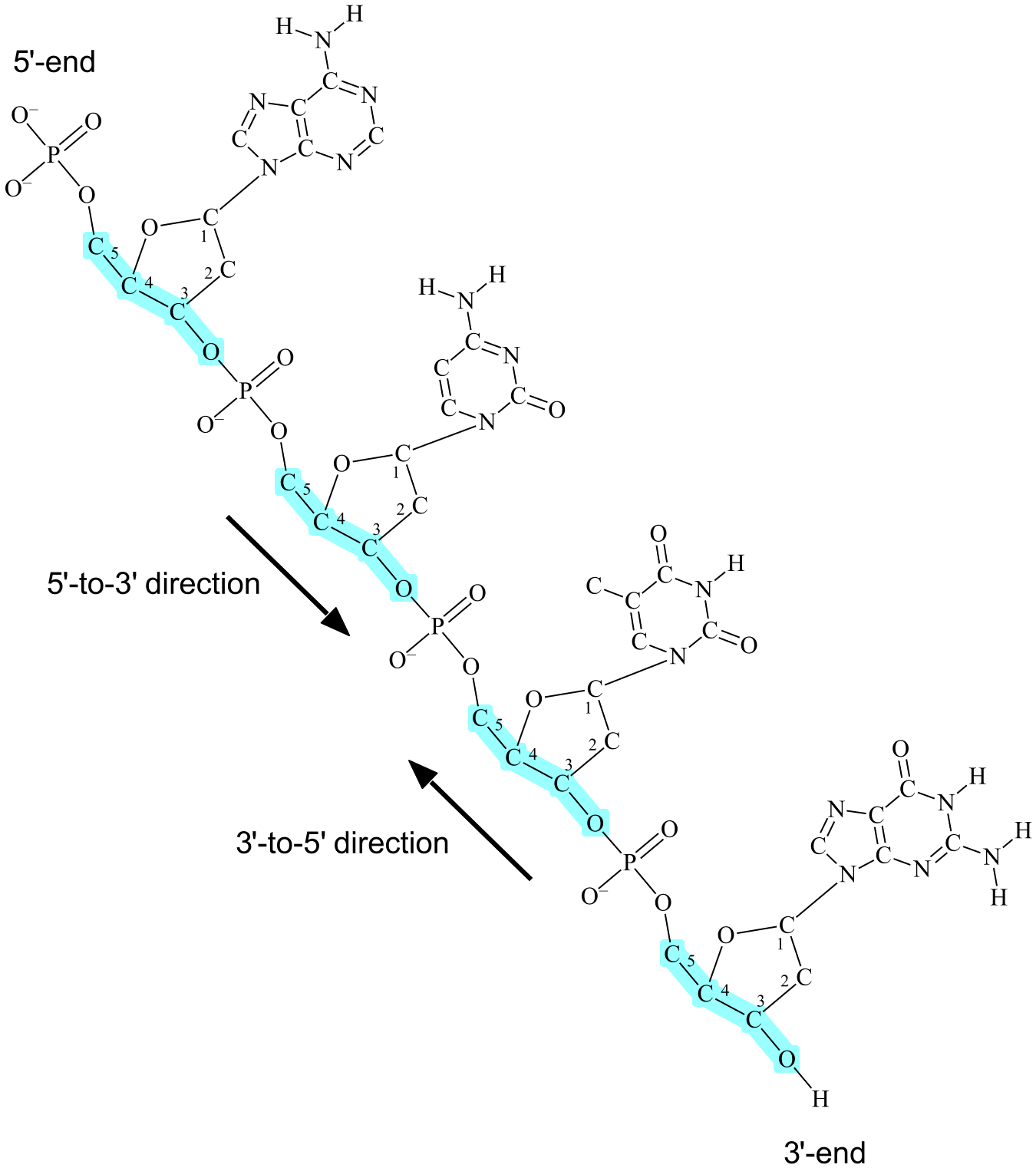
A covalent bond can be established between the 3'-oxygen of one nucleotide and the phosphate of another nucleotide (3'-oxygen is the oxygen attached to the 3'-carbon of deoxyribose). Each nucleotide is therefore able to bind up to two other nucleotides. When nucleotides bind together they create a linear or circular chain called DNA (see Figur 4), and the order of the bases in the chain is called the base sequence of DNA.
(Linear DNA is not necessarily line-shaped, nor is circular DNA necessarily circle-shaped. The words linear and circular rather indicate if the DNA chain has two ends (like a line) or if the chain is without any end (like a circle). In humans, linear DNA exists in the nucleus while circular DNA exists in the mitochondria.)
A DNA chain has two inverse directionalities, both defined by the same three covalent bonds in deoxyribose: the bond between 5'-carbon and 4'-carbon, the bond between 4'-carbon and 3'-carbon, and the bond between 3'-carbon and 3'-oxygen. One of the directions is called 5'-to-3', and is defined as the "path" from 5'-carbon through the three bonds to 3'-oxygen. The other direction is called 3'-to-5' and is defined opposite, i.e. the path from 3'-oxygen to 5'-carbon (see Figure 4).
In a linear chain of DNA, each of the two chain ends are different from the other. At one end of the chain is a nucleotide whose 3'-oxygen is not covalently bound to another nucleotide, this is called the 3'-end of DNA. At the other end is a nucleotide whose phosphate is not bound to another nucleotide, this is called the 5'-end of DNA, as the phosphate is attached to the 5'-carbon of deoxyribose.
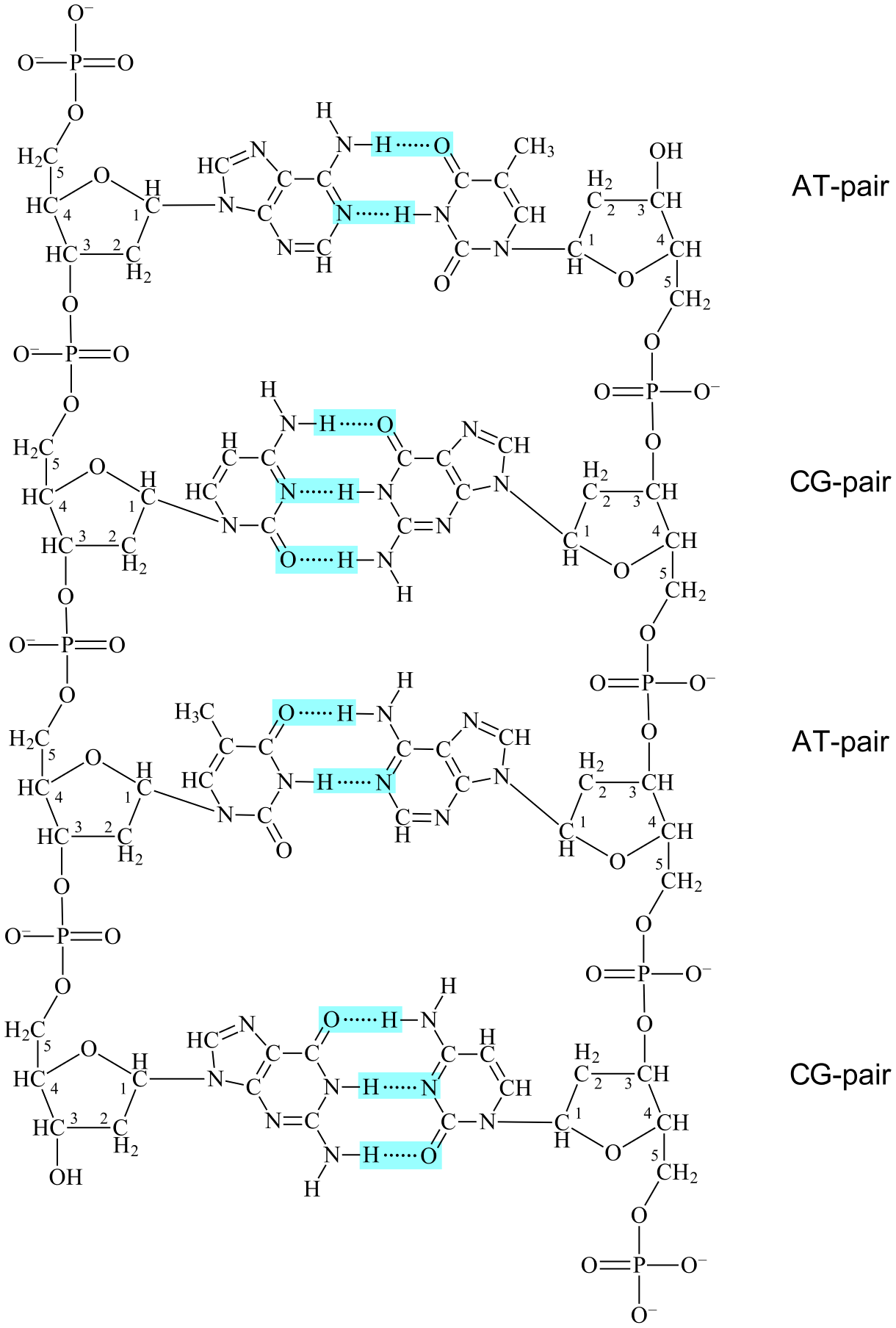
DNA in cells are structured as double helixes, two helix-shaped DNAs held together by hydrogen bonds between the bases (see Figure 5). In these double helixes the following applies:
1. Each Adenine in a DNA has two hydrogen bonds with a Thymine in the other DNA.
2. Each Thymine in a DNA has two hydrogen bonds with an Adenine in the other DNA.
3. Each Cytosine in a DNA has three hydrogen bonds with a Guanine in the other DNA.
4. Each Guanine in a DNA has three hydrogen bonds with a Cytosine in the other DNA.
Since A and T binds together the two are called complementary bases, and an A bound to a T is called a base pair or more spesifically an AT-pair. Similarly, C and G are also called complementary bases and a C bound to a G is called a CG-pair.
Another detail of double helixes is that the two DNAs bind together in reverse directions, meaning that the 5'-to-3'-direction of one DNA is aligned with the 3'-to-5'-direction of the other. This form of binding is called antiparallell. The two DNAs are therefore said to have antiparallell complementary base sequences. (However, the word "antiparallell" is usually not used and one just says that two base sequences are complementary, the antiparallell form of binding being regarded as implicit.)
RNA and genes
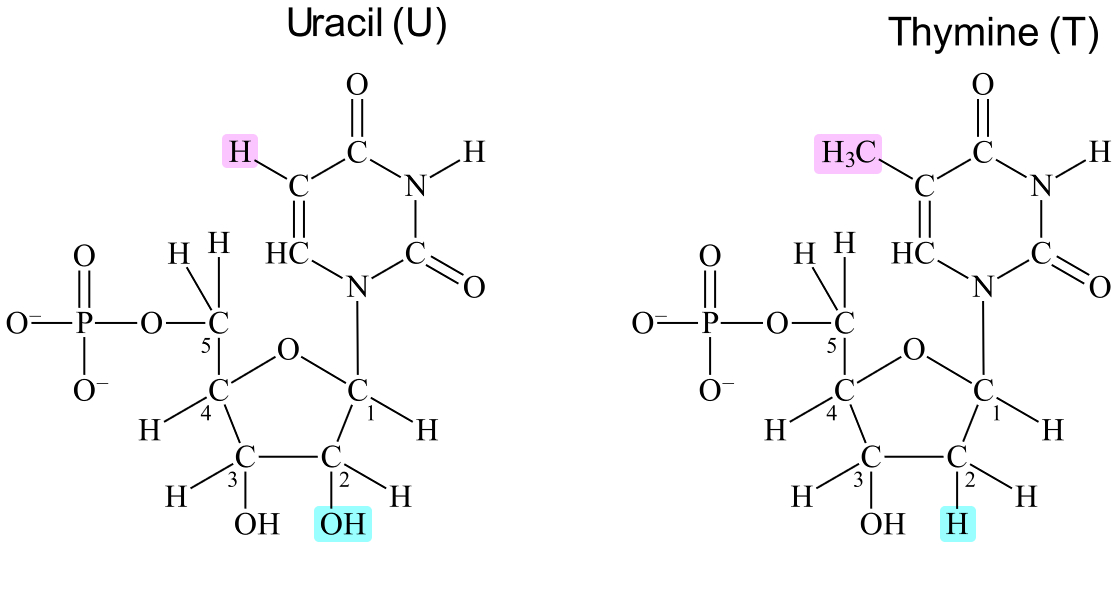
RNA resembles DNA in that both are chains of nucleotides covalently bound together through the 3'-oxygens and the phosphates. The defining difference is that the nucleotides of RNA contain ribose, where a hydroxyl (OH) is attached to the 2'-carbon, while the nucleotides of DNA contain deoxyribose, where a hydrogen (H) is attached to the 2'-carbon (see Figure 6). Deoxyribose means "deoxygenated ribose", as in "a ribose that lacks one oxygen atom".
The most common bases in RNA are adenine, cytosine, guanine, and uracil (the latter is abbreviated as U). This means that three bases (adenine, cytosine and guanine) are common in both RNA and DNA. An RNA can bind to a DNA or another RNA if the two have antiparallell complementary base sequences. In such cases, each uracil in the RNA has two hydrogen bonds with an adenine in the DNA/other RNA. This means that A and U are complementary bases, making A complementary to both T and U.
Synthesis of proteins is accomplished by the aid of genes. A gene is a base sequence in DNA that can be translated to the amino acid sequence of a protein. The translation of a gene to a protein is indirect: the base sequence of DNA is first transcribed ("copied") to RNA, and then the base sequence of RNA is translated to the amino acid sequence of a protein.
Summary
A protein is assembled from different amino acids, and the order of the amino acids determines the three-dimensional structure and the function of the protein. Nucleic acids (DNA and RNA) are similarly assembled from nucleotides arranged in a specific order. Two nucleic acids can bind together through antiparallell complementary base pairing. DNA contains base sequences called genes that can be transcribed to RNA, and the base sequences of RNA can then be translated to the amino acid sequences of proteins.