The Shine-Dalgarno sequence
© Anders Skovly 2025
Of the factors that influence the efficiency of translational initiation in bacteria, the “Shine-Dalgarno sequence” (SD sequence) is the one that receives the most attention, at least in biology textbooks. In this article we will look at how the SD sequence was discovered and how its role in translation was demonstrated. We also take a look at the significance of the position and length of the SD sequence.
Initiation fragments
If copies of a specific mRNA are mixed with ribosomal 30S- and 50S subunits, initiator-tRNAs, and initiation factors, then complete 70S ribosomes can form at the beginning of the messages carried by the mRNA. As long as elongator-tRNAs and elongation factors are absent, the 70S ribosomes cannot move along the mRNAs and will remain bound near the start codons.
Ribonucleases are enzymes that break the covalent bonds holding together the nucleotides in RNA. If ribonucleases are added to the above mixture, most of the mRNA will be cut up. The RNA sequences near the start codons, however, will remain intact as the ribosomes can shield these sequences from the ribonucleases. The shielded sequences are referred to as "initiation fragments".
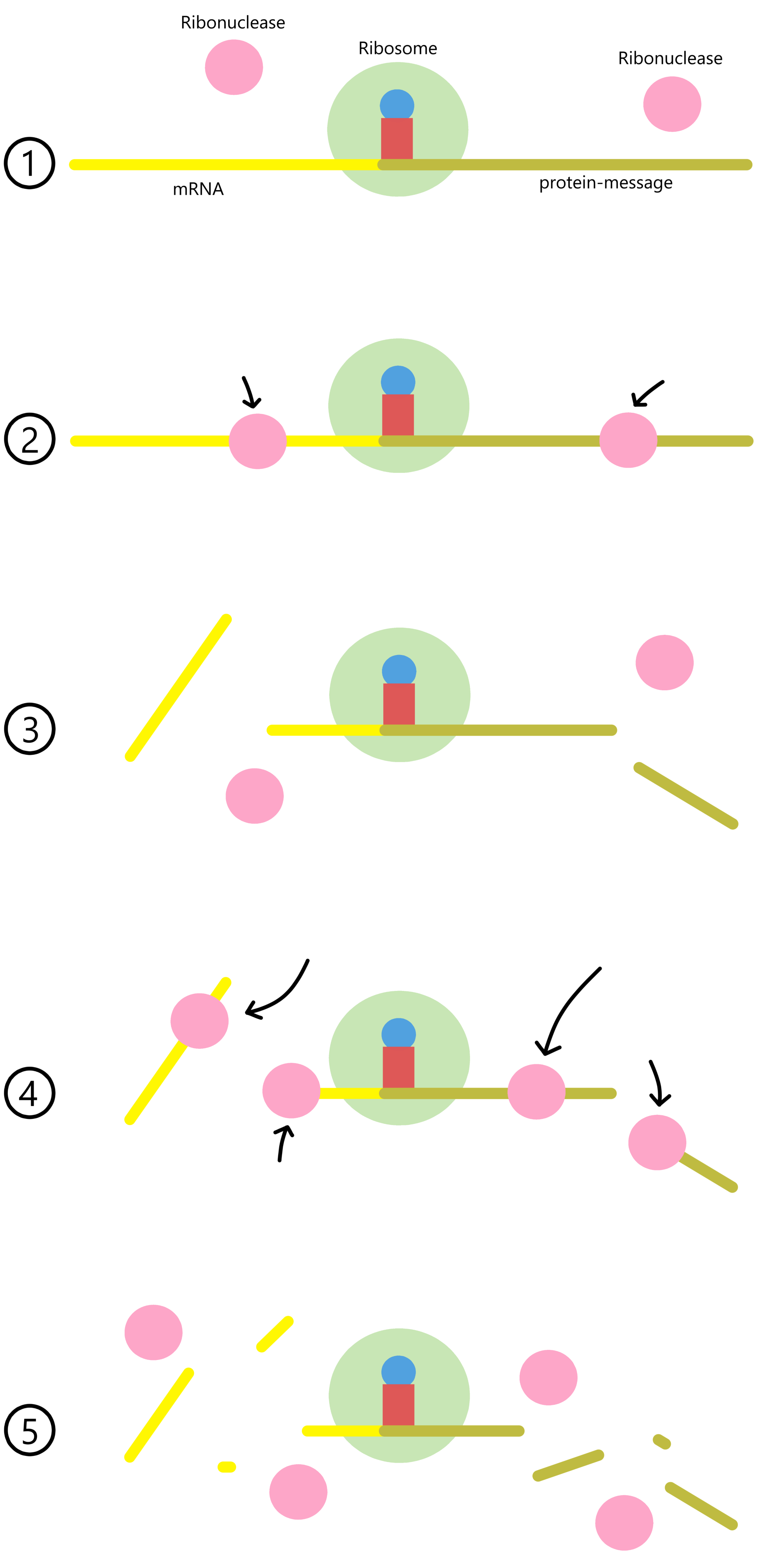
Phage R17 and phage Qβ are viruses that can infect E. coli-cells and use E. coli ribosomes to produce viral proteins. R17 RNA and Qβ RNA both contain three protein messages: the A-protein-message, the Coat-protein-message, and the Replicase-protein-message. Initiation fragments from the three R17 messages were produced, sequenced and published in Steitz 1969. At the same time, the initiation fragment from the Qβ coat-message was produced and the sequence published in Hindley 1969. Other initiation fragment sequences were subsequently published. These sequences were analyzed in Shine and Dalgarno's article, discussed next.
("Initiation fragment" is not the only name used for the shielded sequences. The names "initiator fragment", "initiator region", "initiation site", "ribosome binding site", and "ribosome attachment site" are all used to refer to the shielded sequences in Steitz 1969 and Hindley 1969. In this text I will stick to "initiation fragment".)
Shine, Dalgarno (1974): The 3'-Terminal Sequence of Escherichia coli 16S Ribosomal RNA: Complementarity to Nonsense Triplets and Ribosome Binding Sites
In 1974 John Shine and Lynn Dalgarno published an article presenting the base sequence of the 3’-end of E. coli 16S rRNA (this rRNA is a component of the ribosome’s small (30S) subunit). Their data, when combined with data from other researchers, determined the sequence as 5’-GAUCACCUCCUUA-3’OH. (The "OH" indicates that this is the actual 3'-end of the entire 16S rRNA molecule, as the 3'-ends of RNAs and DNAs contain a free 3' OH-group.)
Shine and Dalgarno noted that in all of the known initiation fragment sequences there existed a short sequence which was complementary to a sequence in the 3’-end of 16S rRNA. In every case this sequence was located just upstream of the start codon. The clearest example of this was found in the initiation fragment from phage R17's A-protein-message, which contained a sequence of seven bases complementary to the 3’-end of 16S rRNA:
|||||||
16S rRNA: 3'OH-AUUCCUCCACUAG-5’
In other initiation fragments the complementary sequence was a bit shorter, some of them four bases long and some of them five bases long. Shine and Dalgarno hypothesized that these complementary sequences might be sites where mRNA and 30S-subunits bind together during translational initiation, and that their base pairing might contribute to making the initiation process faster, so that each round of translation require less time and proteins are produced more quickly.
Steitz, Jakes (1975): How ribosomes select initiator regions in mRNA: Base pair formation between the 3' terminus of 16S rRNA and the mRNA during initiation of protein synthesis in Escherichia coli
Whether or not the two complementary sequences in mRNA and 16S rRNA actually bind together during initiation was tested by Steitz and Jakes in 1975. Central to their work was a protein called Colicin E3. The E. coli 16S rRNA is 1541 nucleotides long, and Colicin E3 can cut this rRNA between the nucleotides at positions 1492 and 1493. The cut produces two rRNA fragments: one long fragment (1492 nucleotides) containing the original 5’-end, and one short fragment (49 nucleotides) containing the original 3’-end.
The essence of the experiment was as follows: mRNA initiation fragments (from the message of phage R17 A-protein) was mixed with ribosomal 30S- and 50S-subunits, initiation factors (IFs), and initiator-tRNAs (i-tRNAs). This caused complete 70S ribosomes to assemble on the mRNA, at the start of the A-protein message. (mRNA initiation fragments will hencefourth be referred to simply as "mRNA".)
Next, Colicin was added to cut the 16S rRNA into fragments. If during translational initiation the 3’-end of the rRNA base pairs with a sequence in the mRNA, then the short 3' rRNA fragment should now remain bound to the mRNA while the long 5' rRNA fragment should no longer be bound.
Sodium dodecyl sulfate (SDS) was added to denature the ribosomal proteins, thereby dissolving the ribosomes into rRNAs and ribosomal proteins. The dissolved ribosomes were analyzed with gel electrophoresis. If mRNA and short 3' rRNA fragments are base paired together, it should be possible to obtain a gel band containing a complex of these two RNAs.
The mixing of mRNA, ribosomal subunits, IFs, and i-tRNAs, followed by treatment with Colicin, was done at a temperature of 30°C. After addition of SDS to dissolve the ribosomes the mixture was placed in ice, and the following gel electrophoresis was performed at a temperature of 6°C.
The cold temperature during ribosome dissolving and gel electrophoresis reduces the rate at which mRNA and other RNA can base pair to each other. After all, the purpose of the experiment is to test whether base pairing between mRNA and the 3'-end of 16S rRNA happens during translational initiation, so base pairing after ribosome dissolution should be inhibited. Lowering the temperature also makes existing base pairs (those formed during translational initiation) more enduring and therefore easier to analyze.
Results: gel columns 1 and 2
After gel electrophoresis, the RNA in the gel was visualized by two different methods. First, the mRNA had been produced with radioactive phosphorus, allowing its positions in the gel to be determined by autoradiography. The radiograph of the gel is shown in Steitz' Figure 2.
Second, a dye called “Stains-all” was applied to the gel. This dye binds to both proteins and RNAs, which allows the gel positions of all ribosomal components to be determined. Steitz does not show the dyed gel, and instead the positions of 5S rRNAs, i-tRNAs, and the small 16S rRNA fragments are indicated on the radiograph (the small 16S rRNA fragments are referred to as “Col” for “Colicin fragments”). The label “0” indicates the start location (where the ribosomal components were initially added before electrophoresis).
Six different samples were applied to the gel. In the first sample (applied to column 1) the mRNA had not been mixed with ribosomal subunits or tRNAs or IFs. The band in column 1 therefore shows the gel position of free mRNA (i.e. mRNA which are not complexed with any other molecule).
In the second sample the mRNA were mixed with ribosomal subunits and tRNAs and IFs, treated with Colicin and SDS, and applied to column 2. Here we see that the band corresponding to free mRNA has become weaker, while a new and slower-moving band appears. The new band assumably contains base paired mRNA and small 3' rRNA fragments.
Results: gel columns 3 and 4
It is possible that the mRNAs bind to the 16S rRNA during translational initiation. But two alternative explanations are also conceivable: first, that a large number of the mRNAs do not bind to the ribosomes, and only bind to small rRNA fragments once the Colicin has cut the small fragments free from the ribosomes. And second, that mRNAs bind to the ribosomes, but not to the 16S rRNAs, and that binding between the mRNAs and small rRNA fragments take place after the ribosomes have been dissolved (in spite of the cold temperature).
Two control samples were created to challenge the alternative explanations. In the first control sample the mRNA, tRNAs, ribosomal subunits and IFs were mixed together with aurintricarboxylic acid, before being treated with Colicin and SDS. Aurintricarboxylic acid has been shown to inhibit mRNA binding to ribosomes. Therefore, the mRNA in this sample will have less opportunity to base pair to rRNA in the ribosome.
If the mRNA base pairs to the 16S rRNAs during initiation, then we can expect the sample with aurintricarboxylic acid to contain a smaller amount of base paired mRNA and small rRNA fragments. If on the other hand one of the two alternative explanations are true, then we can expect that the aurintricarboxylic acid should not make a difference, and that the control sample with this acid should give a gel result similar to the sample in column 2.
The sample with aurintricarboxylic acid was applied to the gel in column 3, and as we can see, the band corresponding to the base paired mRNA/small rRNA fragment is less visible in column 3 than it is in column 2. This opposes the two alternative explanations, and supports the idea that base pairing between mRNA and 16S rRNA takes place during initiation.
In the second control sample, the ribosomal subunits, IFs and tRNAs were mixed together (without mRNA) and treated with Colicin and SDS. The mRNA were added only after the SDS had been added. Again: if the mRNA and 16S rRNA base pairs during initiation, then we can expect this sample to contain a smaller amount of base paired mRNA and small rRNA fragments. While if the second alternative explanation is true (mRNA and small rRNA fragments bind after ribosome dissolving), the late addition of mRNA can be expected to make no difference.
The second control sample was applied to column 4, and we see that the band containing the mRNA fragment complex is again less visible than in column 2, opposing the second alternative explanation.
Results: apparent mRNA degradation
One could think that columns 3 and 4 would contain roughly the same amount of free mRNA as column 1, but this is not the case. In column 3 the band containing free mRNA is very weak compared to the band in column 1. In column 4, on the other hand, the band containing free mRNA is strong, and it might even be that column 4 contains more free mRNA than column 1. It therefore appears that mRNA is being degraded into smaller fragments, with the degradation being most extensive in the control sample in column 3 and least extensive in the control sample in column 4.
It is unknown exactly what is the cause of the degradation. Smaller mRNA fragments produced by degradation can move faster than the “full-size” mRNA initiation fragments, and the smaller fragments should therefore end up further “down” in the gel compared to the full-size fragments. (Whether this is in fact the case or not I cannot tell, because Steitz doesn’t show a picture of the entire gel, only a part of it.)
There is one thing regarding the degradation I can comment on: it makes sense than mRNA degradation would be least extensive in the second control sample (in column 4), for two reasons. In this control sample the mRNA is added late (after addition of SDS), so that whatever is causing the degradation has less time to act. Also, the sample is immediately cooled after mRNA addition, and this cooling would be expected to slow down the degradation process.
Results: gel columns 5 and 6
In the fifth sample Steitz tested what would happen if they mixed mRNA, ribosomal subunits, IFs and i-tRNAs, then added SDS (omitting addition of Colicin, so that the 16S rRNAs aren’t cut into fragments). If mRNA bind to the 3’-end of 16S rRNA, and the rRNA isn’t cut into a small and large fragment, then the mRNA should be base paired to the complete 16S rRNA.
The no-Colicin sample was applied to the gel in column 5, and we see that most of the mRNA did not move out of the start position. This can be explained by the complete rRNA being too large to move through the gel, causing both the rRNA and the base paired mRNA to be retained at the start position. (Steitz states that “Fractionation of the reaction mixture on a sucrose gradient (not shown) rather than on a gel directly supports this conclusion; the mRNA fragments co-sediment with the 16S”.)
In column 5 we also see that the band containing the mRNA complex (the strong band in column 2) is completely absent. This supports the assumption that the molecule bound to the mRNA in column 2 is in fact the small rRNA fragment, as the latter does not exist in the no-colicin sample applied to column 5.
Column 6 contains the same sample as column 2 and therefore produces the same result as column 2 (Steitz doesn't commment on why this particular sample was applied to two columns).
Results: gel column 7
The mRNA used in this experiment are expected to base pair to the 3’-end of 16S rRNA through the sequences 5’-AGGAGGU-3’ (in mRNA) and 5’-ACCUCCU-3’ (in rRNA). According to a theoretical calculation, a temperature of 55°C should be sufficiently hot to “melt”, aka break apart, the base pairs between the two sequences.
In the last sample the mRNA, ribosomal subunits, IFs and i-tRNAs were mixed together, treated with Colicin, and the ribosomes were dissolved with SDS. The dissolved ribosomes were then heated to 55°C for five minutes before being applied to the gel in column 7.
If the mRNA and rRNA are only held together by base pairs between the two mentioned sequences, then the heat treatment should cause the mRNA complexes to separate into free mRNA and free rRNA fragments (assuming that the theoretical calculation is correct). Therefore, if the heat treatment failed to separate the mRNAs and small rRNA fragments, then this would indicate that the two are bound together in a different way, perhaps by a covalent bond.
In column 7 we see that there is no visible band at the position corresponding to the mRNA-rRNA-complexes, while the band containing free mRNA is slightly stronger compared to the same bands in columns 2 and 6. This shows that the mRNA-rRNA-complex does in fact melt during the heat treatment. Strickly speaking, this result does not “prove” that the mRNAs and rRNAs are bound together by base pairing between AGGAGGU and ACCUCCU, but the result does rule out the possibility of a covalent binding between the mRNA and rRNA.
Comment
In column 5, most of the mRNA is located at the start position, which can be explained by the mRNA being base paired to complete 16S rRNAs which are too large to move through the gel. But we also see some mRNA retained at the start position in every other column except in column 1 (that’s the sample that exclusively contained mRNAs).
I’m not sure why this happened. In the case of columns 2 and 6 one might consider that the Colicin did not manage to cut all of the 16S rRNAs, so that a small amount of rRNAs remain complete and can retain a small amount of mRNAs at the start position. But such an explanation cannot be applied to columns 3, 4, and 7. In the samples in columns 3 and 4 the mRNA doesn’t bind to the rRNA, either because of aurintricarboxylic acid inhibiting mRNA binding to ribosomes or because mRNA was only added after the ribosomes were dissolved with SDS. And in the sample in column 7 the heat treatment causes the mRNA-rRNA-complexes to melt into free mRNA and free rRNA fragments. It therefore seems like something other than complete 16S rRNA is retaining some of the mRNA at the start position.
Overall, the results in Steitz and Jakes’ work supports the hypothesis that a sequence in mRNA upstream of a message's start codon can base pair to the 3'-end of 16S rRNA during translational initiation.
SD- and aSD-sequences
At some point (I think in the late 1970's or early 1980's), base pairing between mRNA and the 3'-end of 16S rRNA during initiation became generally accepted as true. When this happened, sequences in mRNA located a few bases upstream of a start codon and complementary to the 3’-end of 16S rRNA started to be referred to as “Shine-Dalgarno sequences” (SD sequences), while a sequence in the 3’-end of 16S rRNA that bind to a SD sequence started to be referred to as an “anti-Shine-Dalgarno sequence” (aSD sequence).
For example, in the case of the message for phage R17 A-protein, the SD sequence is 5'-AGGAGGU-3' and the aSD sequence is 5'-ACCUCCU-3'.
|||||||
rRNA: 3'OH-AUUCCUCCACUAG-5’
Other protein messages can contain other SD sequences that bind to other aSD sequences.
(As mentioned in the section "Initiation fragments", the term "ribosome binding site" is an alternative name for "initiation fragment". However, a lot of texts including biology textbooks use "ribosome binding site" as an alternative name for the SD sequence. This use of the same name for different things can cause unnecessary confusion. Therefore, I think the term "ribosome binding site" should not be used as an alternative name for the SD sequence.)
Stormo, Schneider, Gold (1982): Characterization of translational initiation sites in E. coli
By 1982, the sequences near the start codons of many E. coli messages had been determined. These sequences are compiled in Stormo 1982. In all but one of these messages, the first fifteen bases upstream of the start codons were found to contain a sequence, at least three bases long, which complemented the 3’-end of 16S rRNA. A selection of those E. coli message sequences are shown here:
araC: 5’-GGGAGUAUGAAAAGUAUG-3’ (length=4, spacer=10)
pheA: 5’-CAAAAAGGCAACACUAUG-3’ (length=3, spacer=7)
recA: 5’-AUGACAGGAGUAAAAAUG-3’ (length=5, spacer=5)
rpsD(S11): 5’-CGGGGUGAUUGAAUAAUG-3’ (length=6, spacer=6)
trpR: 5’-CAAUGGCGACAUAUUAUG-3’ (no SD sequence)
(As pointed out in Schurr 1993, SD- and aSD sequences don't necessarily need to be continous. At least in theory, the base paired SD-aSD-sequences can include bulged nucleotides or looped nucleotides. An example of a bulged nucleotide is shown in Schurr's Figure 1. One can see that in the case of rpsD, the presense of a bulge in the aSD sequence could allow the SD sequence of rpsD to be extended to 5'-GGGGUGAU-3'. This complication with bulges and loops will be ignored in this article, as it is not ultimately of importance here.)
Hui, de Boer (1987): Specialized ribosome system: Preferential translation of a single mRNA species by a subpopulation of mutated ribosomes in Escherichia coli
(While support for binding between the SD- and aSD sequences has been presented in Steitz 1975, I haven't yet shown that this binding actually contributes towards making the initiation process faster. For now, let's just assume that this is the case. The results presented in this section will support the assumption.)
The 3'-end of 16S rRNA has the sequence 5'-GAUCACCUCCUUA-3’OH. Many mRNAs have SD sequences that can bind to at least three of the bases 5'-CCUCC-3' in 16S rRNA. For example, the SD sequence upstream of the lacZ message, AGGA, can bind to the aSD sequence UCCU, involving three of the five CCUCC-bases:
||||
16S rRNA: 3'OH-AUUCCUCCACUAG-5’
Therefore, mutation of the CCUCC sequence in 16S rRNA that prevents its base pairing to SD sequences can be expected to reduce the efficient of translational initiation for many mRNAs.
What if the CCUCC in 16S rRNA was mutated so that it cannot bind the SD sequence, and a complementary mutation was introduced to the SD sequence of a protein message, restoring its ability to base pair with the mutated 16S rRNA? Would this restore the efficiency of initiation for that single specific protein message? This is what Hui and de Boer tried to do: create E. coli-cells with mutant ribosomes that translates a specific mutant message more efficiently than other messages present in the cells.
Method
Chromosomal DNA in E. coli contains seven genes for 16S rRNA, those genes being rrsA, rrsB, rrsC, rrsD, rrsE, rrsG, rrsH. A plasmid containing a copy of the rrsB gene was inserted into a culture of E. coli-cells, giving the cells a total of eight genes for 16S rRNA.
The inserted plasmid also contained a hGH gene with an SD sequence of GGAGG. The hGH mRNA transcribed from this gene would serve as the "single specific mRNA" mentioned earlier. Thus, the plasmid contained a hGH gene with the SD sequence GGAGG, and an rrsB gene with with the aSD sequence CCUCC. This will be referred to as the "reference plasmid".
Two other plasmids were also created. In one, the SD sequence of hGH had been mutated to CCUCC, while the aSD sequence of rrsB had been mutated to GGAGG. This will be referred to as the "inverted plasmid". In another, the SD had been mutated to GTGTG, while the aSD had been mutated to CACAC. This will be referred to as the "alternative plasmid". The two plasmids were inserted into each their culture of E. coli-cells.
In all three plasmids, transcription of the rrsB gene was controlled by the lambda PL operator sequence together with the lambda cI857 repressor protein. The cI857 repressor is active at a temperature of 30°C and will bind to the PL operator to prevent transcription of plasmid rrsB. At a higher temperature, such as 38°C, the cI857 repressor cannot maintain its active structure and is no longer able to bind to the PL operator. The plasmid rrsB gene is therefore transcribed at 38°C. The seven chromosomal genes for 16S rRNA are transcribed regardless of temperature.
This means that at 30°C all ribosomes contains 16S rRNA transcribed from the seven chromosomal genes, with the un-mutated aSD sequence CCUCC. At 38°C, some ribosomes contains 16S rRNA transcribed from the seven chromosomal genes, with the un-mutated aSD CCUCC, while other ribosomes contains 16S rRNA transcribed from the plasmid rrsB gene, with aSD sequence of CCUCC or GGAGG or CACAC (depending on the plasmid).
(The plasmid hGH gene was not subject to any repression and was transcribed all the time regardless of temperature. It was therefore expected that the concentration of hGH mRNA would be fairly constant, and that a change in the production of hGH protein as the temperature is increased could not be caused by an increase in the concentration of hGH-mRNA.)
The three E. coli-cultures were first grown at a temperature of 30°C, before the temperature was raised to 38°C. The translation of the hGH message was assessed indirectly by measuring the concentration of hGH protein in each of the three cultures. (hGH protein is human growth hormone, a protein that is not naturally present in E. coli. Therefore, all measured hGH protein derive from translation of the plasmid hGH gene.)
Results
The concentration of hGH protein is shown in Hui and Boer’s Figure 3, where timepoint 0 is the moment when the temperature was raised from 30°C to 38°C.
Measurements from the culture with the reference plasmid, represented in the figure by △, show that translation of the hGH message in this culture is relatively high at 30°C and remains high at 38°C (i.e. the message is being translated efficiently regardless of temperature). This was the expected result, since a message with an SD sequence of GGAGG can be translated by ribosomes containing 16S rRNA from the chromosomal genes (which are transcribed regardless of temperature).
Measurements from both the culture with the inverted plasmid, represented by ◆, and from the culture with the alternative plasmid, represented by ●, show that translation of hGH messages with mutated SD sequences CCTCC or GTGTG is very low at 30°C. That is as expected, as messages with such SD sequences cannot bind to the aSD sequence of 16S rRNA from the chromosomal genes, and at 30°C all ribosomes contain such 16S rRNAs.
Once the temperature is raised to 38°C in the cultures with inverted or alternative plasmids, the plasmid rrsB genes are transcribed, and some of the new ribosomes that are assembled will contain aSD sequences GGAGG or CACAC. We can see that at this temperature the translation of the hGH messages becomes more efficient, as indicated by the gradual accumulation of hGH protein. This result supports the idea that the SD-aSD base pairing makes the initiation process faster, so that translation in general becomes faster.
An unexpected result is that at the 3 hours mark, the concentration of hGH protein is roughly double in the culture with the alternative plasmid, compared to the culture with the inverted plasmid. This suggests that, for whatever reason, the SD and aSD sequences present in the alternative plasmid (SD:GTGTG/aSD:CACAC) function better than the sequences present in the inverted plasmid (SD:CCTCC/aSD:GGAGG).
Controls
For the cultures with the inverted plasmid and alternative plasmid, Hui and Boer considered the possibility that the increased concentration of hGH protein at 38°C was unrelated to transcription of the mutated plasmid rrsB genes. They thought that the increase in temperature from 30°C to 38°C might cause some unpredicted change in the E. coli-cells, and that this could be responsible for the increase in hGH concentration. To test this possibility, two control plasmids were created.
One control plasmid contained a hGH gene with the mutated SD sequence CCTCC (like the inverted plasmid) while another control plasmid contained a hGH gene with the mutated SD sequence CACAC (like the alternative plasmid). What differentiated the control plasmids from the inverted and alternative plasmids was that the control plasmids did not contain a rrsB gene.
If increased concentration of hGH protein at 38°C was unrelated to transcription of the plasmid rrsB gene, then the removal of the plasmid rrsB gene should have no influence on the hGH concentration. Consequently, the two control cultures containing the control plasmids should have the same hGH concentration as the cultures containing the inverted plasmid and alternative plasmid.
Measurements of hGH protein in the two control cultures, represented by □ and ○, shows that translation of hGH messages with mutated SD sequences do not increase as the temperature changes from 30°C to 38°C. Translation of hGH messages with mutated SD must therefore be dependent on ribosomes with mutated aSD sequences (i.e. dependent on transcription of the plasmid rrsB gene).
(In my opinion the control plasmids should ideally have contained un-mutated rrsB genes with an aSD sequence of CCTCC, to ensure that different SD sequences of the hGH genes was the only variable among the two control plasmids and the reference plasmid.)
Jacob, Santer, Dahlberg (1987): A single base change in the Shine-Dalgarno region of 16S rRNA of Escherichia coli affects translation of many proteins
(I think the results obtained in Jacob 1987 aren't actually that interesting, and they are included here mainly due to Jacob's use of two-dimensional gel electrophoresis. I plan to write an article about gel electrophoresis in the near future and wanted a practical example of 2D-gelelectrophoresis, hence why this article is included.)
As we saw in the last section, Hui and Boer tested how a five-base mutation in 16S rRNA affected the translation of a single protein message, the hGH message. Jacob performed a somewhat similar experiment, testing how a single-base mutation in the 16S rRNA of E. coli affects translation of multiple different messages. In unmutated 16S rRNA the sequence of the 3’-end is:
while in the mutant used in Jacob's experiment the sequence was:
The mutated rrsB gene was inserted into a plasmid. Transcription of the rrsB gene was controlled by the lambda PL operator sequence together with the lambda cI857 repressor protein. The plasmid was inserted into a culture of E. coli-cells. A control culture containing a plasmid with an unmutated rrsB gene was also created.
While the two cell cultures were growing at 42°C to permit transcription of the plasmid rrsB genes, radioactive [35S]methionine was added to the cultures to make newly produced proteins radioactive. The cells were given 20 minutes to incorporate [35S]methionine into proteins before all proteins were extracted from both cultures. The two protein extracts were analyzed by two-dimentional gel electrophoresis (first separating the proteins in one dimension with isoelectric focusing, then separating the proteins in a second dimension by mass).
Results
The gels are shown in Jacob’s Figure 4, where 4a is the gel containing proteins from the control culture, and 4b is the gel containing proteins from the mutant culture.
Jacob's analysis of the protein patterns focuses on a few select spots that fulfill two criteria: First, the spot must only contains a single type of protein, and that protein must be known (such information is obtained from the earlier works of other researchers). For example, the gel spot marked with “A” contains a protein called “alpha subunit of (Ca2+,Mg2+)-ATPase” (short name: AtpA). Second, the SD sequence of the protein’s message must be known. According to Jacob’s table 1, the SD sequences of AtpA is:
(Two potential SD sequences in bold where either sequence may be functional. The start codon is underscored. If a bulging base is permitted in the aSD sequence then an SD sequence of 5'-AGGGG-3' may also be functional.)
At the time the experiment was performed, only AtpA and seven other proteins fulfilled both criteria. They’re all listed in Jacob's table 1. (For some reason, only five of the eight proteins are marked on the gel in Jacob's figure 4. In my comments on the result I will ignore the three proteins that are not marked on the gel.)
As already mentioned, the gel spot marked “A” contains AtpA. This spot is smaller (contains less protein) in figure 4b than in 4a, suggesting that the 16S rRNA mutation reduces translation of this protein. The SD sequences of the AtpA message may base pair with 16S rRNA in either of two ways:
|||
rRNA: 3’OH-AUUCCUCCACUAG-5’
or alternatively:
||||
rRNA: 3’OH-AUUCCUCCACUAG-5’
With the mutant 16S rRNA, the ability of the sequences to base pair is reduced:
| |
rRNA: 3’OH-AUUCUUCCACUAG-5’
or alternatively:
| ||
rRNA: 3’OH-AUUCUUCCACUAG-5’
The reduced amount of AtpA protein in the culture containing mutated 16S rRNA therefore correlates with a reduced base pairing between the SD- and aSD sequences.
The gel spot marked “D” contains the protein AtpB (the beta subunit of (Ca2+,Mg2+)-ATPase). As with AtpA, the AtpB protein shows a correlation with reduced spot size in figure 4b and reduced base pairing between the SD sequence and the mutated ASD sequence.
The spot marked “B” contains methionyl-tRNA synthetase (MetRS), and in this case the spot is bigger (contains more protein) in figure 4b than in 4a, suggesting that the 16S rRNA mutation increases translation of this protein. The SD sequence of the MetRS message can base pair with 16S rRNA like this:
|||| ||
rRNA: 3’OH-AUUCCUCCACUAG-5’
With the mutant 16S rRNA the ability of the sequences to base pair is increased:
|||||||
rRNA: 3’OH-AUUCUUCCACUAG-5’
The increased amount of MetRS in the culture containing mutated 16S rRNA therefore correlates with increased base pairing between the SD- and aSD sequences.
(The spot marked “C” contains ribosomal protein S1. We see that in figure 4a this spot has a long trail on the left side, whereas the spot in 4b does not have any such trail. I don’t feel like the relative amount of protein in the two spots can be visually gauged when the spot shapes differ in this way, so I exclude the "C" spot from comment.)
The spot marked “E” contains S-adenosyl-methionine synthetase (MetK). This spot has a fairly similar size (similar amount of protein) in both figure 4a and 4b, suggesting that the mutation in 16S rRNA does not influence translation of this protein. The SD sequence of the MetK message can base pair with 16S rRNA like this:
||||||
rRNA: 3’OH-AUUCCUCCACUAG-5’
With the mutant 16S rRNA the base pairing remains unchanged:
||||||
rRNA: 3’OH-AUUCUUCCACUAG-5’
The unchanged amount of MetK therefore correlates with a lack of change in SD-aSD-pairing in the mutant 16S rRNA compared to the unmutated rRNA.
While Jacob's results are compatible with Shine and Dalgarno’s hypothesis, I think the work is held back by the inability at the time to analyze a larger set of proteins. It would have been interesting to see if the correlation between protein amount and SD-aSD-base pairing could be maintained in a larger set of proteins.
Chen, Bjerknes, Kumar, Jay (1994): Determination of the optimal aligned spacing between the Shine-Dalgarno sequence and the translation initiation codon of Escherichia coli mRNAs
Different protein-messages have different distances ("spacings") between the SD sequence and the start codon. For example, E. coli's recA-message has a spacer of five nucleotides between the SD sequence and the start codon, the rpsD-message has a spacer of six nucleotides, the lacZ-message has seven, and the araC-message has ten.
rpsD: 5’-CGGGGUGAUUGAAUAAUG-3’ (spacer:6)
lacZ: 5’-ACACAGGAAACAGCUAUG-3’ (spacer:7)
araC: 5’-GGGAGUAUGAAAAGUAUG-3’ (spacer:10)
Chen thought that the base pairing between the SD- and aSD sequences might function to align the start codon with the anticodon of the initiator-tRNA in the ribosome's P-site, to facilitate base pairing between start-codon and anticodon during translational initiation. If this is correct, there should presumably exist an optimal spacer length between the SD sequence and the start-codon, a length that equals the distance between the aSD sequence and the anticodon/P-site. The goal of Chen's experiment was to identify this optimal spacer length.
The search for the optimal spacer is complicated by the fact that different SD sequences bind to different aSD sequences, which will have different distances from the P-site/anticodon. For example, let's for a moment assume that there is a seven-base distance between the P-site and the aSD sequence UCCU (I'm not saying that this is true, the assumption is only for the purpose of demonstration). If this is the case, then the start-codon of the lacZ-message will be perfectly aligned with the P-site:
tRNAfMetUAC
16S rRNA: 3'OH-AUUCCUCCA-5' UAC
|||| |||
lacZ: 5’-ACACAGGAAACAGCUAUG-3’
Now take a look at the pheA-message. Like the lacZ-message, the pheA-message has a 7-base spacer between the SD sequence and the start codon:
But when the SD sequence of the pheA message base pairs to the 16S rRNA, the start codon will not be perfectly aligned with the P-site as was the case for the lacZ-message, even if both messages have a 7-base spacer:
tRNAfMetUAC
16S rRNA: 3'OH-AUUCCUCCA-5' UAC
|||
pheA: 5’-CAAAAAGGCAACACUAUG-3’
This means that if one managed to find the optimal spacer length for one particular SD sequence, other SD sequences should have different optimal spacers.
To generalize about optimal spacer length it is therefore necessary to utilize the concept of "aligned spacing". The base A1534 is chosen as an arbitrary point of reference (this is an Adenine that is base #1534 when counting from the 5'-end of 16S rRNA, or base #9 when counting from the 3'-end). Aligned spacing refers to the number of bases that separate a message's start-codon from the base that aligns with A1534. For example, the lacZ-message has an aligned spacing of four bases:
16S rRNA: 3'OH-AUUCCUCCA-5' UAC
|||| : |||
lacZ: 5’-ACACAGGAAACAGCUAUG-3’ (aligned spacing: 4)
While the pheA-message has an aligned spacing of three bases:
16S rRNA: 3'OH-AUUCCUCCA-5' UAC
||| :
pheA: 5’-CAAAAAGGCAACACUAUG-3’ (aligned spacing: 3)
If the function of the SD-aSD-binding is indeed to align the start-codon with the P-site/anticodon, then there might exist an optimal aligned spacing that is universal for all SD sequences. This because the distance between A1534 and the P-site/anticodon is independent of the SD sequence.
(While in the above figures it appears that the start-codon of the pheA-message cannot align with the P-site, this isn't really the case. The mRNA and the ribosome are not completely rigid structures, they have some flexibility. This makes it possible for the start-codon to align with the P-site even with suboptimal spacers, although the alignment will take more time.)
Method
A protein-message with an optimally spaced SD sequence can be expected to have a higher rate of translation than the same message with a longer or shorter spacing. In Chen's experiment, the message for the CAT-protein was used to test different spacings. Translation of the CAT-message can be determined indirectly by measuring the activity of the CAT-protein (chloramphenicol acetyltransferase).
Chen used oligonucleotide synthesis to produce two series of short DNAs. The d-series contained the SD sequence TAAGG and the start codon AUG, and was made in eleven different spacer lengths, while the D-series contained the SD sequence GAGGT and the start codon AUG, and was made in nine different spacer lengths (see Chen's Figure 3). Each of the twenty short DNAs from the two series were used to replace the SD sequence and start codon in a CAT-gene in a plasmid, and the resulting twenty plasmids were transformed into each their E. coli-culture.
Results
The activity of the CAT-protein was measured in every culture (see Chen's Figure 4). For the SD sequence GAGGT the activity was highest when the spacer was five bases long, and the activity steadily falls off for spacers longer or shorter than five. For the SD sequence TAAGG the CAT activity was highest when the spacer was nine bases long, and again the activity falls off steadily for spacers longer or shorter than nine. In both cases the CAT activity was highest when aligned spacing was five bases long. This supports the hypothesis about the SD-aSD-pairing functioning to position the start-codon in the ribosomal P-site.
Chen notes two weaknesses in the experiment. One is that the concentration of CAT-mRNA is not measured, and it is therefore possible that different spacer lengths influence transcription or degradation of CAT-mRNA. This would affect the CAT-activity.
The other weakness is that the length of the sequence upstream of the start codon, i.e. the length of the message's "leader sequence", can influence the rate of translation. While the length of the spacer varies between 2 and 17 bases, the length of the leader sequence varies from 35 to 50 bases. Ideally the leader should have a constant length regardless of the spacer length. In practice, this means that messages with shorter spacers should contain additional bases upstream of the SD sequence.
Another noteworthy detail of the experiment is that the culture with the D-series of plasmids (SD:GAGGT) has a maximal CAT-activity of 0.9 units, while the culture with the d-series (SD:TAAGG) only has a maximal CAT-activity of 0.4 units. It was not known what was the cause of this disparity.
Vimberg, Tats, Remm, Tenson (2007): Translation initiation region sequence preferences in Escherichia coli
To determine how the length of the SD sequence influences the efficiency of translation, the SD length was varied from 1 base to 8 bases (see Vimberg's Figure 1). Each SD sequence was placed in front of a gene for GFP (green fluorescent protein) in a plasmid which was inserted into an E. coli-culture. The concentration of GFP in each culture was determined by measuring the culture's fluorescence, while the concentration of GFP-mRNA was determined by quantitative polymerase chain reaction. Translational efficiency of GFP is presented as the GFP "expression level", the amount of GFP produced per mRNA.
When E. coli was cultured at a temperature of 37°C, the 6 bases long SD sequence 5'-AGGAGG-3' gave the highest expression (see Vimberg's Figure 2). The 1 base long SD "sequence" containing a single G expectedly gave the lowest expression. Each length increase from 1 to 2 to 3 to 4 to 5 to 6 caused an increase in expression. Further length increases from 6 to 7 and from 7 to 8 both caused a reduction in expression.
The effect of SD length was found to be dependent on the presence or absence of a so-called "enhancer-sequence" upstream of the SD sequence. With no enhancer, the 6-bases long SD was about 1.5 to 2.5 times more effective than the 1-base SD. When combined with the most effective enhancer, the 6-bases long SD was about ten times more effective than the 1-base SD.
As the length of the SD sequence increases, the base pairing between the SD- and aSD sequences becomes more stable, making it more effective at positioning the start codon in the ribosomal P-site. It is possible that if the SD sequence becomes "too long" and the SD-aSD-binding becomes "too stable", then it will be difficult for the ribosome to break free from the SD sequence to start moving along the mRNA during translational elongation. This may explain the reduction in expression seen in SD sequences of lengths 7 and 8 compared to the SD sequence of length 6.
E. coli was also cultured at 20°C, and at that temperature it was the 5 bases long SD sequence 5'-GGAGG-3' that gave the highest expression (see Vimberg's Figure 3). It is not only increased sequence length that increase the stability of the SD-aSD-binding, reduced temperature also increase the stability. The result at 20°C therefore supports the notion that it is excessive SD-aSD-stability that causes reduced expression in the longest SD variants.
Saito, Green, Buskirk (2020): Translational initiation in E. coli occurs at the correct sites genome-wide in the absence of mRNA-rRNA base-pairing
So far in this article we've seen results that provide good support for the idea that the SD- and aSD-sequences bind together during initiation, and that the binding stability and the positions of the two sequences can influence the efficiency of translation. Some significant questions have not been answered yet: out of the approximately 4300 genes in E. coli, how many genes have SD-sequences? And for those genes that do have SD-sequences, does the binding stability and positions of the SD- and aSD-sequences correlate well with the translational efficiency of those genes? In this last section we shall see the answer to one of those questions.
Saito used "ribosome occupancy" as a measure of translational efficiency in a large set of E. coli messages. The ribosome occupancy of a message refers to how close together the ribosomes are packed along the message (remember that a message can be translated by multiple ribosomes simultaneously). A shorter distance between adjacent ribosomes means closer packing, i.e. higher ribosome occupancy, and indicates higher translational efficiency.
For each message, the "strength" of its SD sequence was calculated as −ΔG. (ΔG, the change in free energy, here represents the thermodynamic stability of the base paired SD-aSD-sequences, with lower (more negative) values of ΔG indicating greater stability. Therefore, higher (more positive) values of −ΔG indicate greater stability.) Across the whole set of messages analyzed, only a weak correlation (0.11) was found between ribosome occupancy and SD strength (see Saito's Figure 2A).
The ribosome occupancy of the messages was also tested in a second E. coli culture containing ribosomes with mutations in the 3'-end of 16S rRNA. The CCUCC-sequence in the 3'-end had been changed to AAAAA, preventing the mutated ribosomes from binding to the SD sequences of the messages. For this culture, a strong negative correlation (−0.50) was found between ribosome occupancy and SD strength. (see Saito's Figure 2B. Note that SD strength in Figure 2B represents the binding stability between the SD sequence and the un-mutated aSD sequence, not the binding stability between the SD and mutant aSD.)
In other words, in the second culture containing mutated ribosomes that don't bind to SD sequences, messages with weaker SD sequences are translated more efficiently than messages with strong SD sequences. One possible explanation of this result is that strong SD sequences correlated with factors that reduce translational efficiency.
For each message in the set, Saito calculated the difference in ribosome occupancy between the culture with normal ribosomes and in the culture with mutated ribosomes. This difference in ribosome occupancy had a strong positive correlation (0.68) with SD strength (see Saito's Figure 2C). That is to say that in general, the stronger the SD sequence of a message, the greater the gain in translational efficiency of ribosomes that can bind to the SD over ribosomes that can not.
Overall, the results presented in Figure 2A, 2B and 2C shows that while the SD-sequences contribute to translational efficiency of messages in E. coli, the strength of the SD-sequences is generally not used to tune translational efficiency of individual messages (because strong SD sequences tend to correlate with factors that reduce translational efficiency).
References
Hindley, Staples
(1969): Sequence of a Ribosome Binding Site in Bacteriophage Qβ-RNA. Paid article
Schurr, Nadir, Margalit
(1993): Identification and characterization of E.coli ribosomal binding sites by free energy computation. Free article
Steitz
(1969): Polypeptide chain initiation: nucleotide sequences of the three ribosomal binding sites in bacteriophage R17 RNA. Paid article